
首语
抖音,是由今日头条孵化的一款音乐创意短视频社交软件。该软件于2016年9月20日上线,是一个面向全年龄的短视频社区平台。
作为抖音的重度使用患者,每天刷着视频笑哈哈😄,不亦乐乎。可是大家都知道,抖音下载的视频是带水印的。作为一个有强迫症的程序猿,这是绝对不允许的。网上许多的去水印工具,它们的原理是咋样的,是写了一种特别厉害的算法嘛。好奇心驱使我开始了研究。
短视频去水印
分析
我们从抖音的分享链接入手,从抖音复制的分享链接格式如下:
2.82 wsr:/ Happy birthday to Kobe.%篮球 %曼巴精神 %科比生日 https://v.douyin.com/d8LpxMQ/ 复制佌鏈接,da鐦Dou音搜索,直接观看視频!
其中有个链接地址 https://v.douyin.com/d8LpxMQ/,我们放到浏览器里,发现这个链接重定向了,重定向的地址如下:
好像也没啥用,我们抓下包看看有没有请求视频的接口,仔细找找找,叮。发现了 item_ids 的接口,后面跟的值就是重定向url的最后这部分(6999605370222054663),我判断这应该是视频的ID了。接口地址如下:
https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6999605370222054663
接下来我们看看这个接口请求返回的数据,哇哦,当我点开Preview的时候,一下豁然开朗了,有视频的文案、作者、音乐、缩略图、地址等等。

我拿出视频的地址后,复制到浏览器打开。视频url如下:
可是打开后发现,视频左上角的水印还是在啊。看着这个url中的 playwm,发现 wm和我项目名有点相似,不是watermark的缩写吗?我去掉 wm,然后复制到浏览器打开,神奇的一幕出现了,视频的水印没了,太激动了。视频无水印的地址如下:
https://aweme.snssdk.com/aweme/v1/play/?video_id=v0d00fg10000c4hpfk3c77uar6l7cs90&ratio=720p&line=0
原来抖音视频去水印这么简单啊,还想着视频算法什么的,只是简单分析就搞成了。哈哈,简单的让我有点感动🤭。
既然原理搞明白了,那写代码不是轻松加愉快嘛。
代码实现
- 我们复制的视频链接是一个混合文本的视频短链接,首先将链接提取出来,这个就用正则来处理吧。
if len(re.findall('[a-z]+://[\S]+', content, re.I | re.M)) > 0:
return re.findall('[a-z]+://[\S]+', content, re.I | re.M)[0]
- 视频短链接提取出来后,需要对其进行请求重定向,来获取视频的
id。通过request库来进行请求。
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/92.0.4515.107 Safari/537.36'}
# url:重定向的url
response = requests.get(url, headers=header)
return response.url
- 我们需要对重定向得到的url进行截取视频
id,来作为接口参数item_ids的值。
# realUrl:重定向得到的url
startUrl = realUrl[0:realUrl.index('?')]
id = startUrl[startUrl.rindex('/') + 1:len(startUrl)]
- 开始请求接口。GET请求,一个参数
item_ids。
douyinUrl = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo'
douyinParams = {
'item_ids': id
}
douyinResponse = requests.get(url=douyinUrl, params=douyinParams, headers=headers)
body = douyinResponse.text
- json解析,拿到视频文案和视频地址。其中无水印视频链接的
playwm要替换成play。
data = json.loads(body)
# 视频文案
videoTitle = data['item_list'][0]['desc']
# 视频带水印url
videoUrl = data['item_list'][0]['video']['play_addr']['url_list'][0]
# 视频无水印url
realVideoUrl = f'{videoUrl}'.replace('playwm', 'play')
- 最后,我们通过
webbrowser库来打开浏览器,并播放视频,尽情享受无水印的快感吧。
webbrowser.open(realVideoUrl)
所有代码如下:
import json
import re
import webbrowser
import requests
def get_url(content):
if len(re.findall('[a-z]+://[\S]+', content, re.I | re.M)) > 0:
return re.findall('[a-z]+://[\S]+', content, re.I | re.M)[0]
return None
def get_redirect_url(url, header):
# url:重定向的url
response = requests.get(url, headers=header)
return response.url
if __name__ == '__main__':
douyinUrl = 'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/92.0.4515.107 Safari/537.36'}
inputContent = input('请输入视频链接:')
if inputContent.strip() is not None:
if get_url(inputContent) is not None:
realUrl = get_redirect_url(get_url(inputContent), headers)
# realUrl:重定向得到的url
startUrl = realUrl[0:realUrl.index('?')]
id = startUrl[startUrl.rindex('/') + 1:len(startUrl)]
douyinParams = {
'item_ids': id
}
if realUrl.__contains__('www.douyin.com/video'):
douyinResponse = requests.get(url=douyinUrl, params=douyinParams, headers=headers)
body = douyinResponse.text
print(douyinResponse.url)
data = json.loads(body)
print(data['item_list'][0]['desc'])
# 视频文案
videoTitle = data['item_list'][0]['desc']
# 视频带水印url
videoUrl = data['item_list'][0]['video']['play_addr']['url_list'][0]
# 视频无水印url
realVideoUrl = f'{videoUrl}'.replace('playwm', 'play')
print(realVideoUrl)
webbrowser.open(realVideoUrl)
用户列表视频批量去水印
分析
通过上面视频去水印的基础,我们继续深入研究用户个人主页视频去水印。
我悄悄去复制了雷总(雷军)首页的分享链接。雷总的抖音主页简介是“热爱是所有的理由和答案。”,正如我热爱技术一样🤭。
首页分享的链接内容如下:
在抖音,记录美好生活! https://v.douyin.com/d8NLmmR/
接下来我们在浏览器中重定向分享url,重定向url如下:
这么可能一下看不出来啥信息,放在postman里看下请求参数。
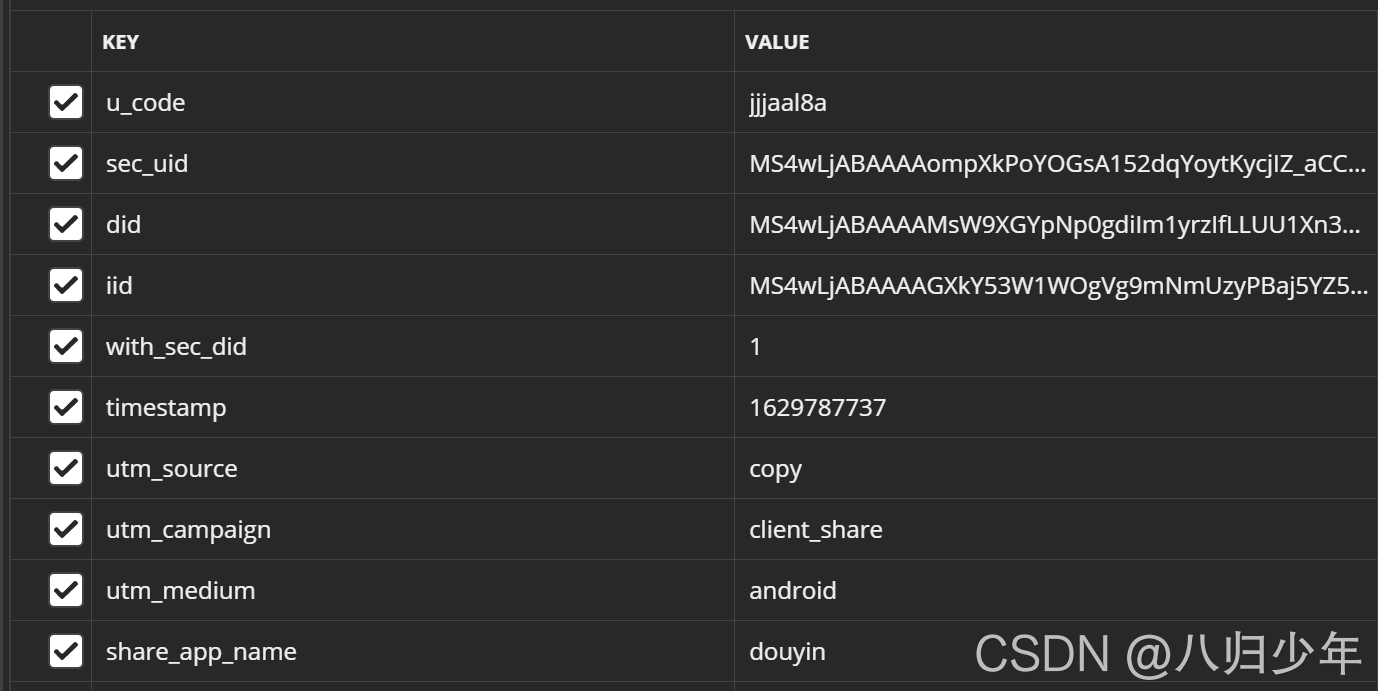
这样一看,暴露出来许多参数。接下来继续抓包,仔细找找视频列表的接口,找找找。叮,一个接口映入我的眼帘,Preview 里有视频信息的列表数据。视频列表接口url如下:
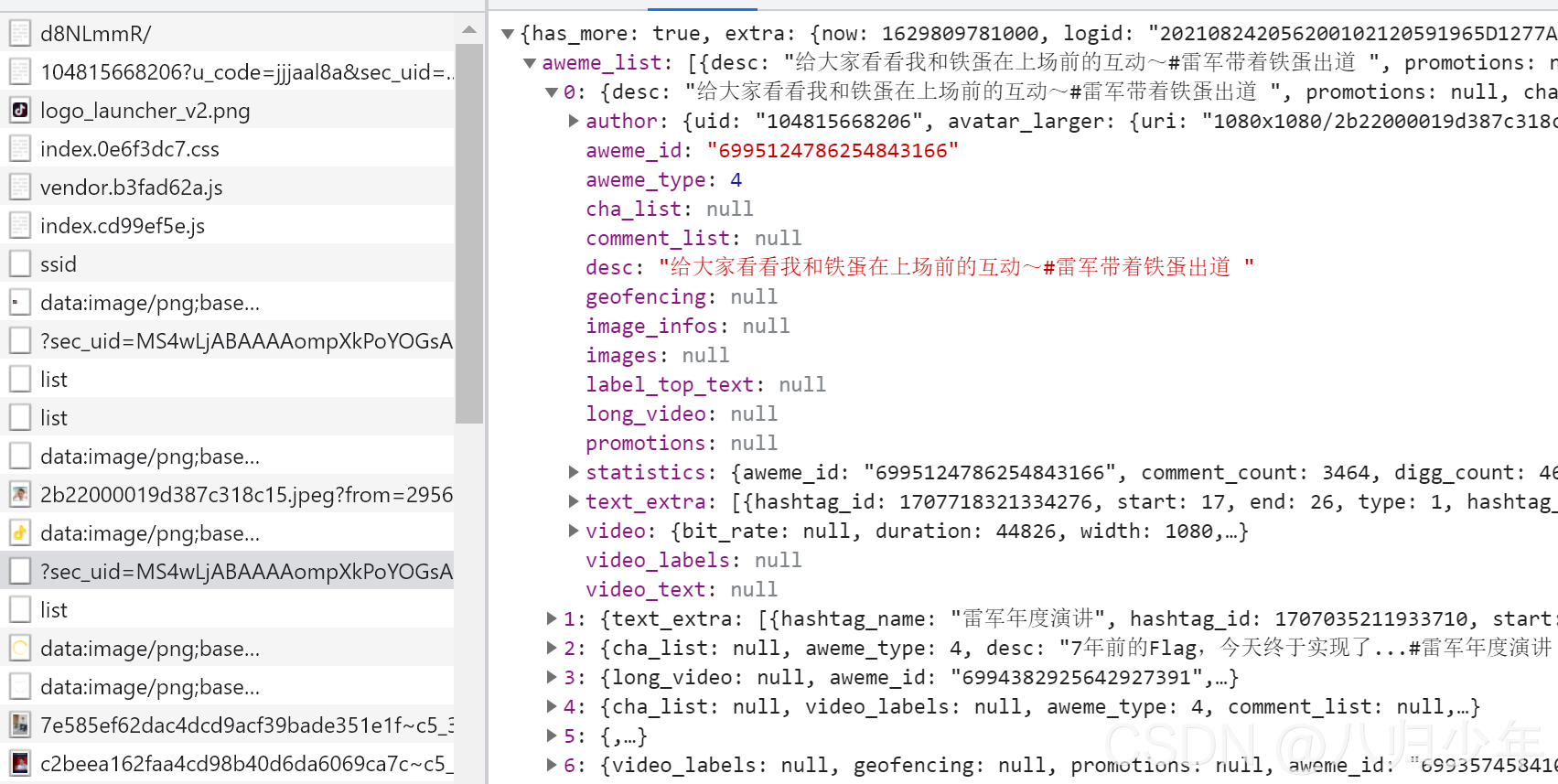
请求参数如下:

仔细分析各个参数的含义,sec_uid 和重定向url里 sec_id 含义一样,count 肯定是每次查询数量,它肯定也是分页查询。max_cursor 就是游标呗,用于查询下一页。这个值接口每次会返回。aid 不清楚。_signature 应该是加密的一个签名。dytk 不清楚。
不清楚的这几个参数怎么办呢,GET请求去掉会怎么样呢。把后面这三个参数去掉,再去请求,神奇的一幕发生了,接口依然通着。我复制了几个链接更换 sec_uid,还是没有问题。这?批量获取就成功了,哈哈哈。去掉后的接口如下:
接下来,开始写代码。
代码实现
链接提取、请求重定向和 sec_uid 值截取代码同上。
- 开始请求接口,获取视频列表。GET请求,三个参数。
douyinUrl = 'https://www.iesdouyin.com/web/api/v2/aweme/post/'
douyinParams = {
'sec_uid': id,
'count': 24,
'max_cursor': 0,
}
response = requests.get(url=douyinUrl, params=douyinParams, headers=headers)
body = response.text
- json解析,获取视频列表所有的文案和视频地址,这里获取的直接是无水印的视频地址。
data = json.loads(body)
for content in data['aweme_list']:
if len(content['video']['play_addr']['url_list']) > 0:
print(content['desc'] )
print(content['video']['play_addr']['url_list'][0])
- 获取下一页视频列表。只是参数
max_cursor发生了变化。请求和获取视频列表所有文案及视频地址同上。
douyinParams = {
'sec_uid': id,
'count': 24,
'max_cursor': data['max_cursor'],
}
- 接口中有个字段
has_more,它是用来判断是否有更多视频,has_more=true时,代表视频获取完。
if data['has_more']:
print('无视频')
exit()
- 这里我优雅的处理了一下视频的文案和地址,前面只是打印在控制台上。我通过在本地创建一个
douyin.md文件,然后通过markdown语法,以链接的形式写入到douyin.md文件中,这样看到文案的同时,点击文案可以播放视频。markdown链接语法示例如下:
[视频文案](视频地址)
写入代码如下:
for content in data['aweme_list']:
with open('douyin.md', 'a', encoding='utf-8') as f:
if len(content['video']['play_addr']['url_list']) > 0:
f.write(
'[' + content['desc'] + ']' + '(' + content['video']['play_addr']['url_list'][0] + ')' + ' <br />')
- 最后,看下我获取到的雷总部分的视频列表截图。

怎么样,还不错吧!有喜欢的小姐姐视频可以悄悄保存下来慢慢看哦🤭,哈哈哈。
总结
我觉得很多东西都是这样,没研究之前总感觉深不可测,研究技术的原理时,才发现如此简单。这说明,绝大多数事,只要肯研究,都能搞明白个大概。
告诉一个小秘密哦,可能已经不是秘密了。。。快手短视频的去水印处理方式类似,只是批量获取时要加入 cookie,我已经实现了代码,有感兴趣的小伙伴可以自行尝试,有问题的可以私信我。
声明
本篇博客只用于Python学习,如有侵权,可联系我立即删除。切勿用于商业用途,如有使用,所产生的后果与博主无关。



